A Fast LinkedList in Rust: Part 2 - Performance
I've designed and implemented a Doubly LinkedList in Rust that's fast and allows adding and removing nodes in the middle of list in constant time.
The deepmesa::collections::LinkedList maintains a free list of nodes and so does not have to allocate and deallocate memory everytime an element is added or removed from the list. This also allows the list to return Handles to nodes in the list and these handles are guaranteed to remain valid even between mutations of the list.
This design makes the list twice as fast as the std::collections::LinkedList.
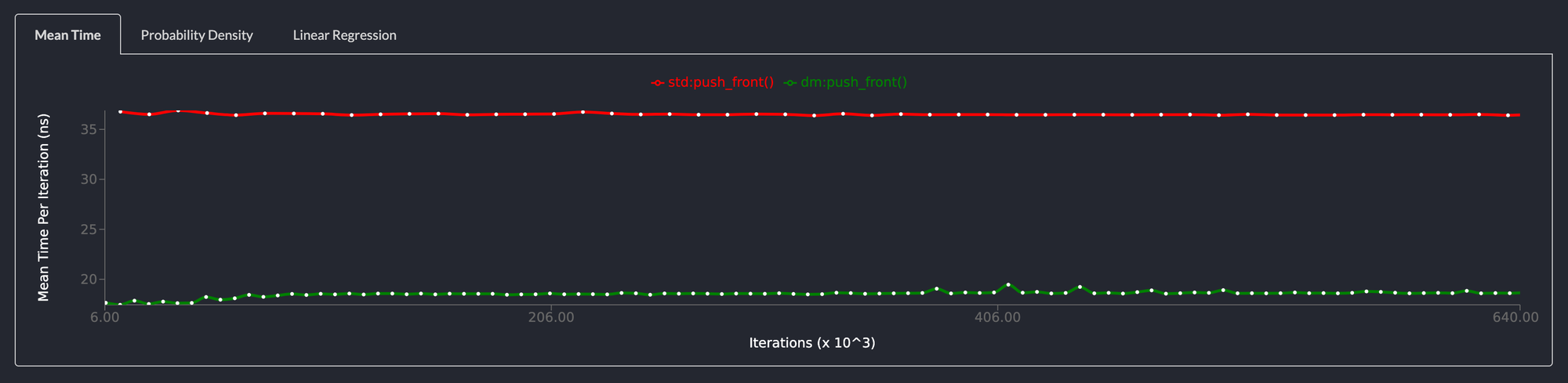
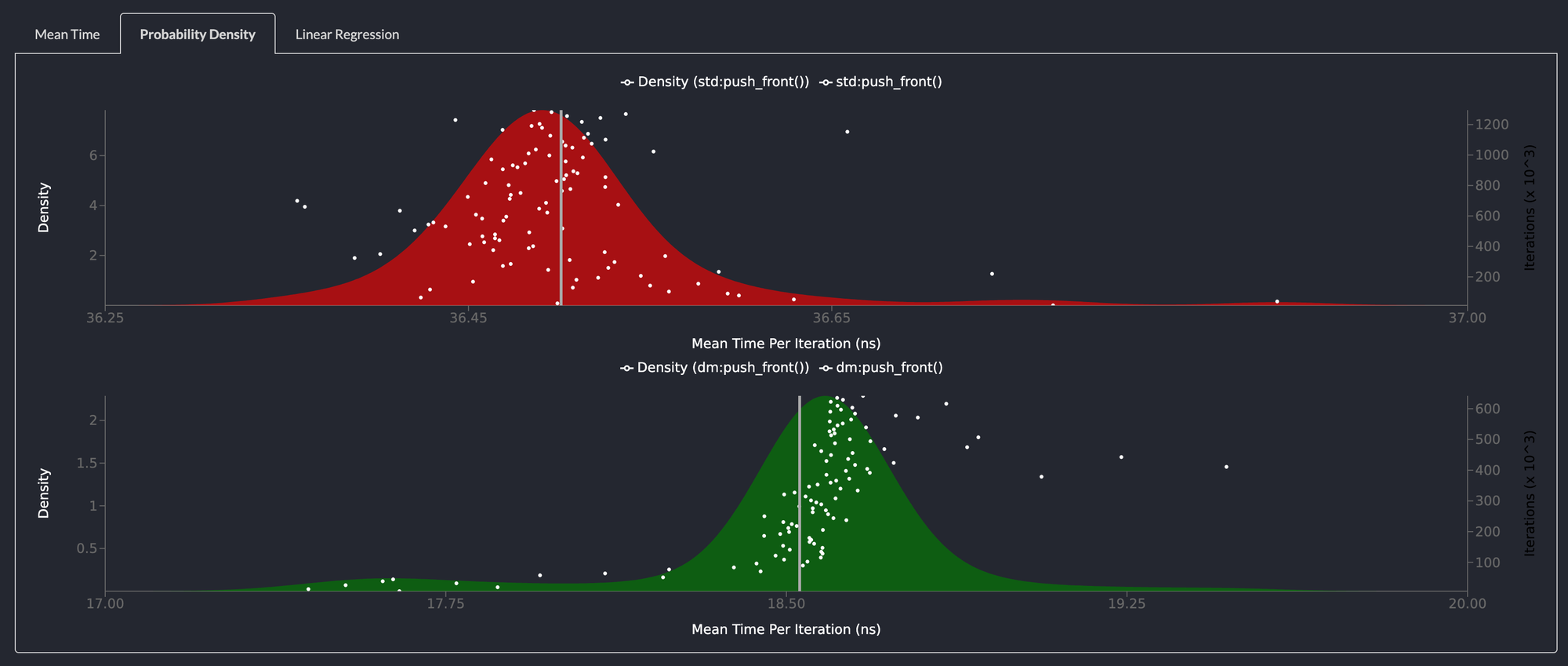
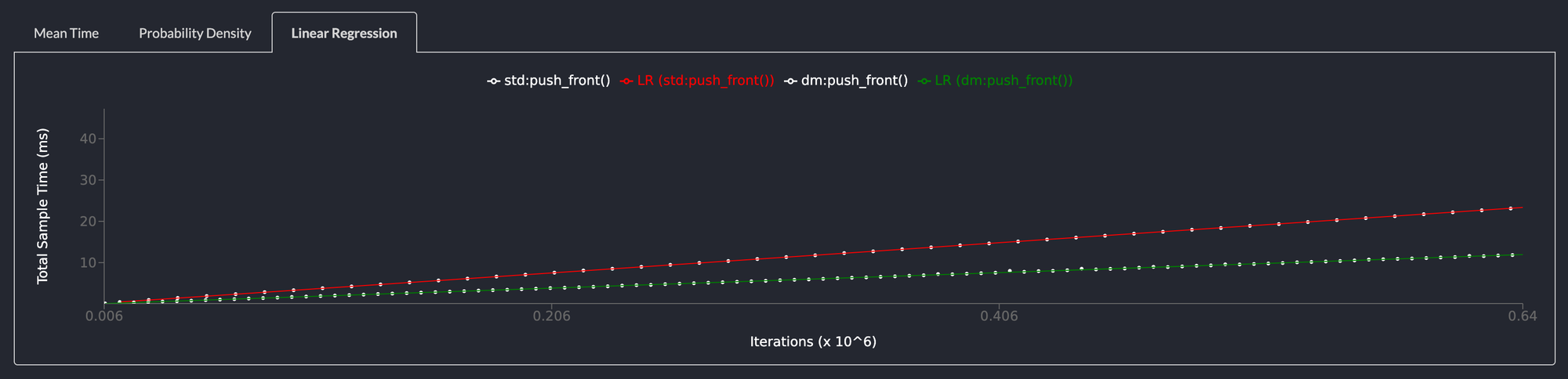
push_front() is 2x faster than std::collections::LinkedList
Pushing an element to the front of the list returns a NodeHandle to the element added to the list. This operation is twice as fast as the same operation on the std::collections::LinkedList.
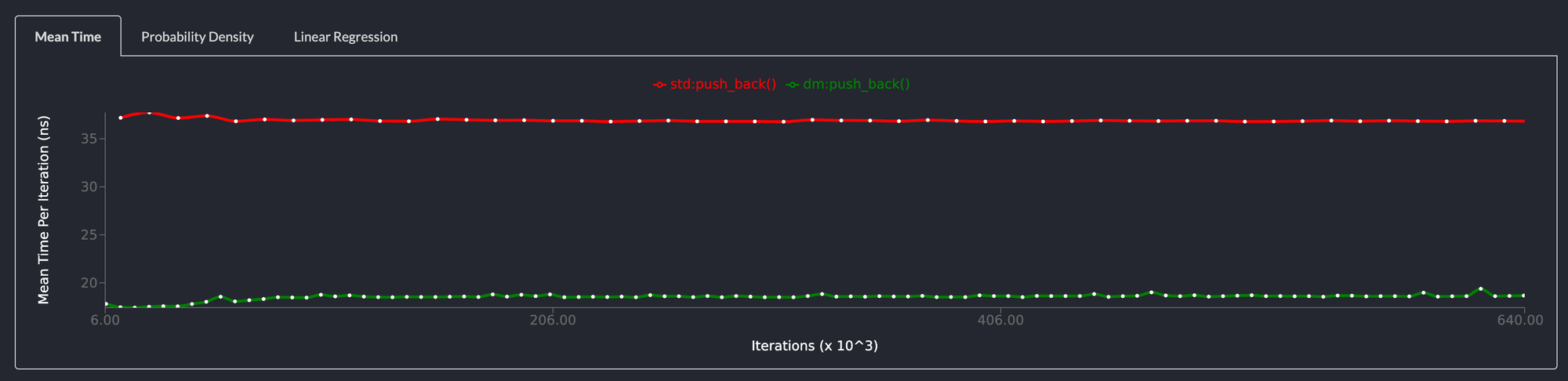
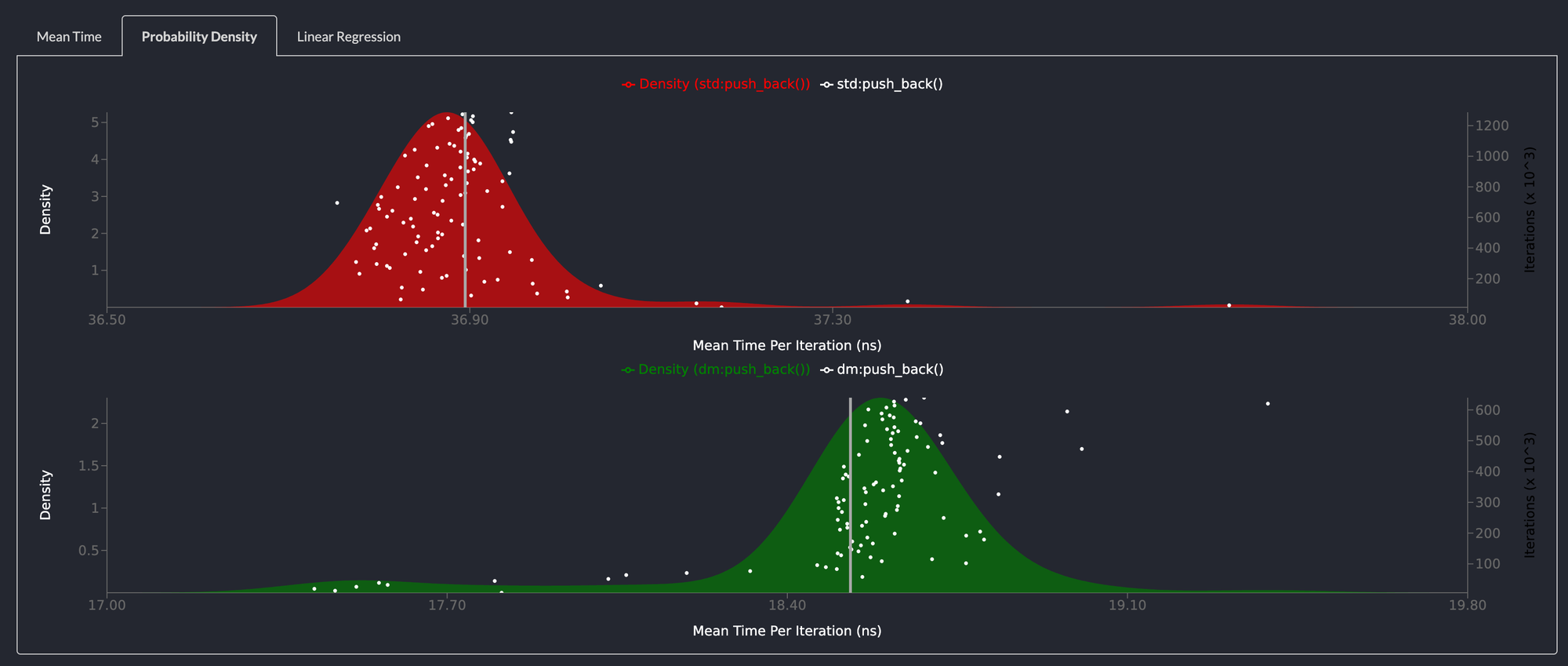
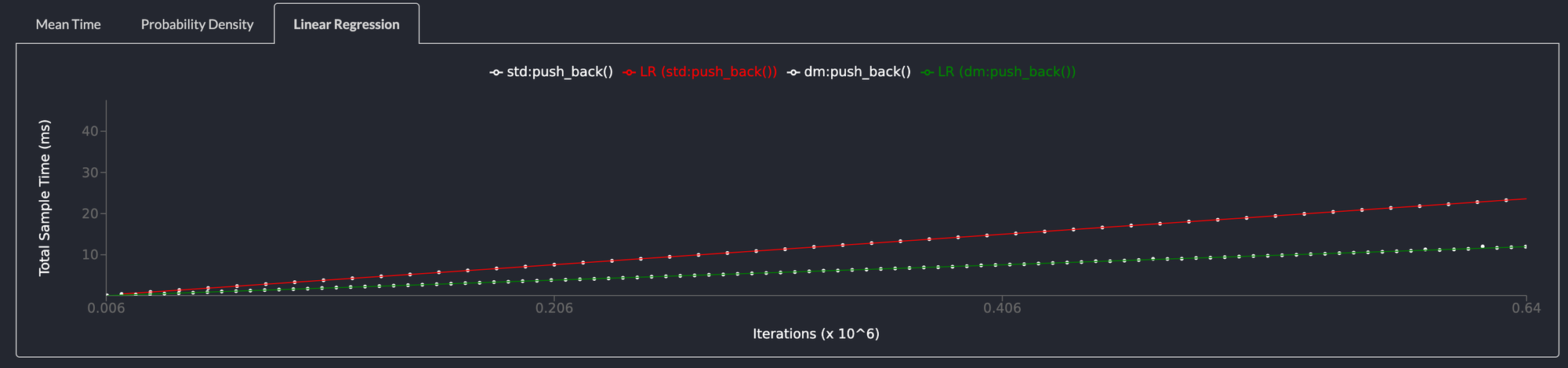
push_back() is 2x faster than std::collections::LinkedList
Similarly, pushing an element to the back of the list is twice as fast and for the same reason. Allocating and deallocating memory is expensive and the deepmesa LinkedList allocates memory upfront and reuses memory from a free list.
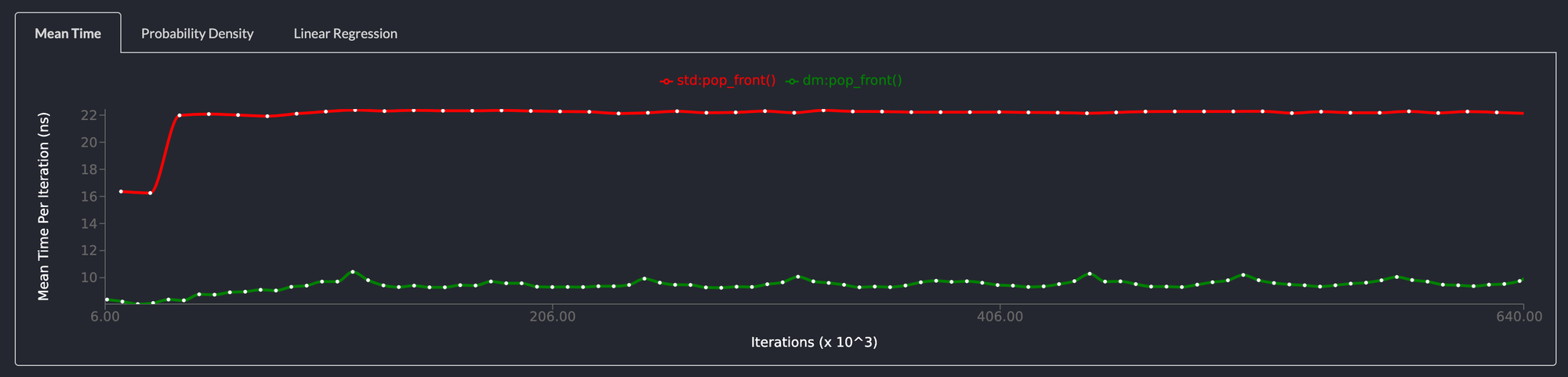
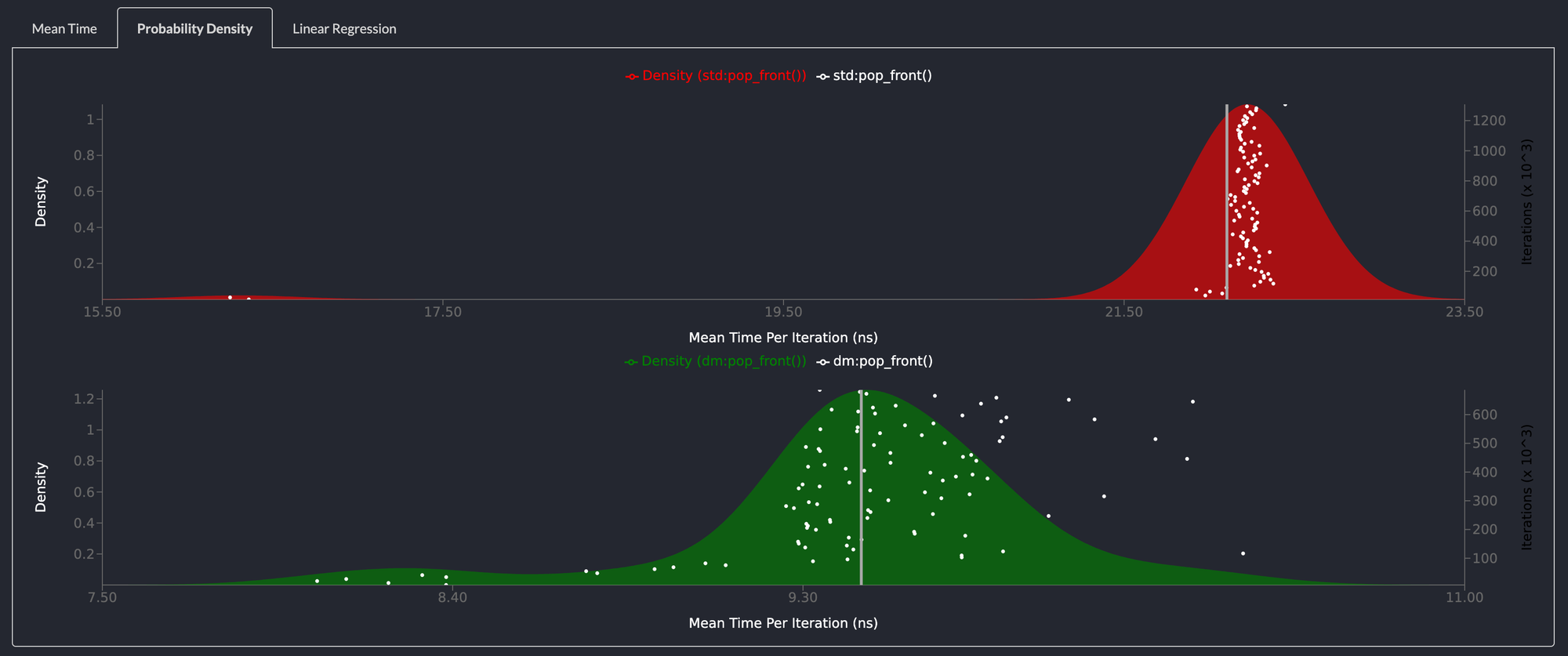
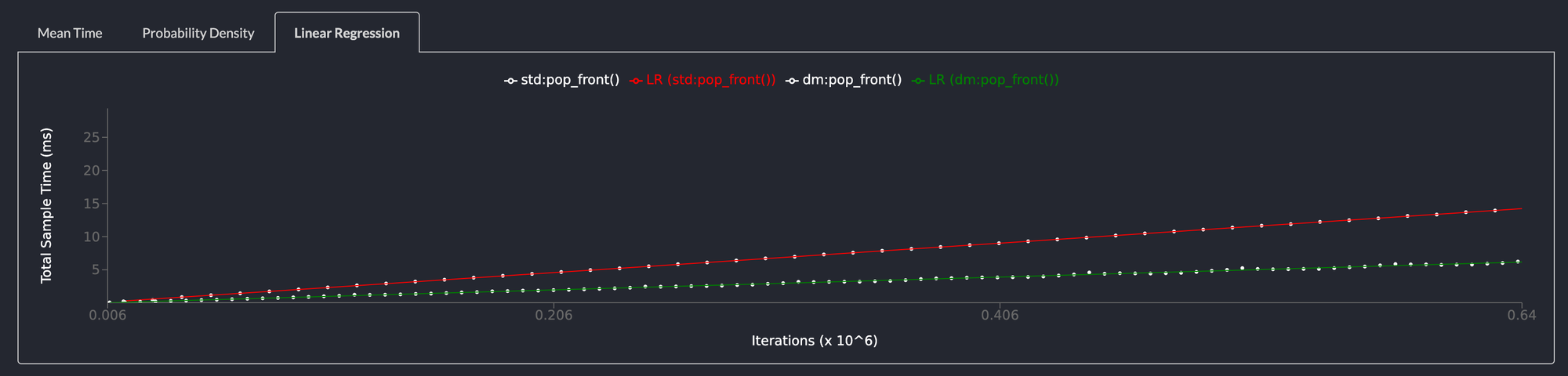
pop_front() is more 2x as fast as std::collections::LinkedList
Popping elements from the front of the list is even faster than the standard library linked list. This is attributable to the fact that the LinkedList in the standard library has to deallocate memory everytime an element is removed from the list. The deepmesa linked list, merely has to update a few pointers.
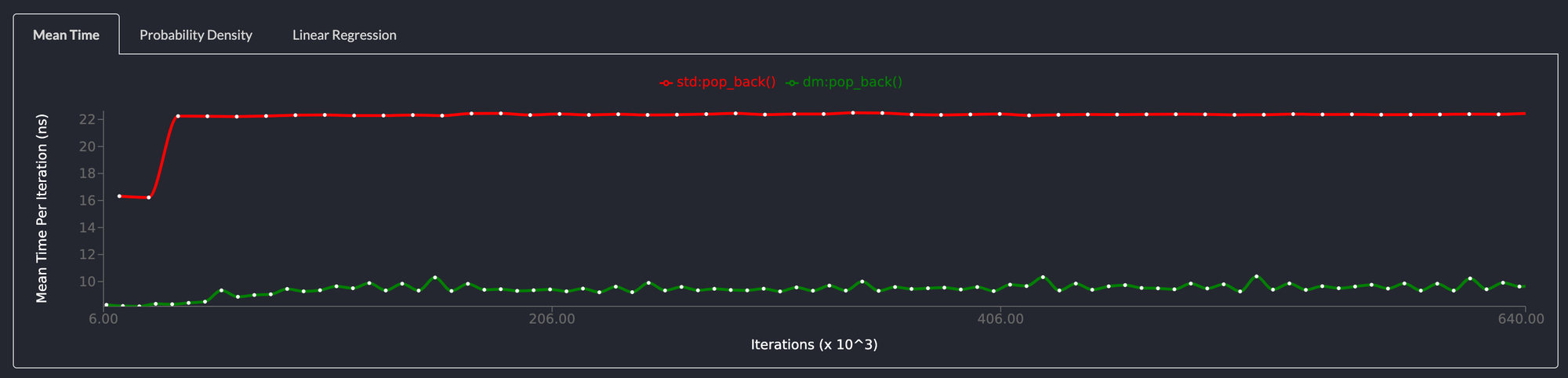
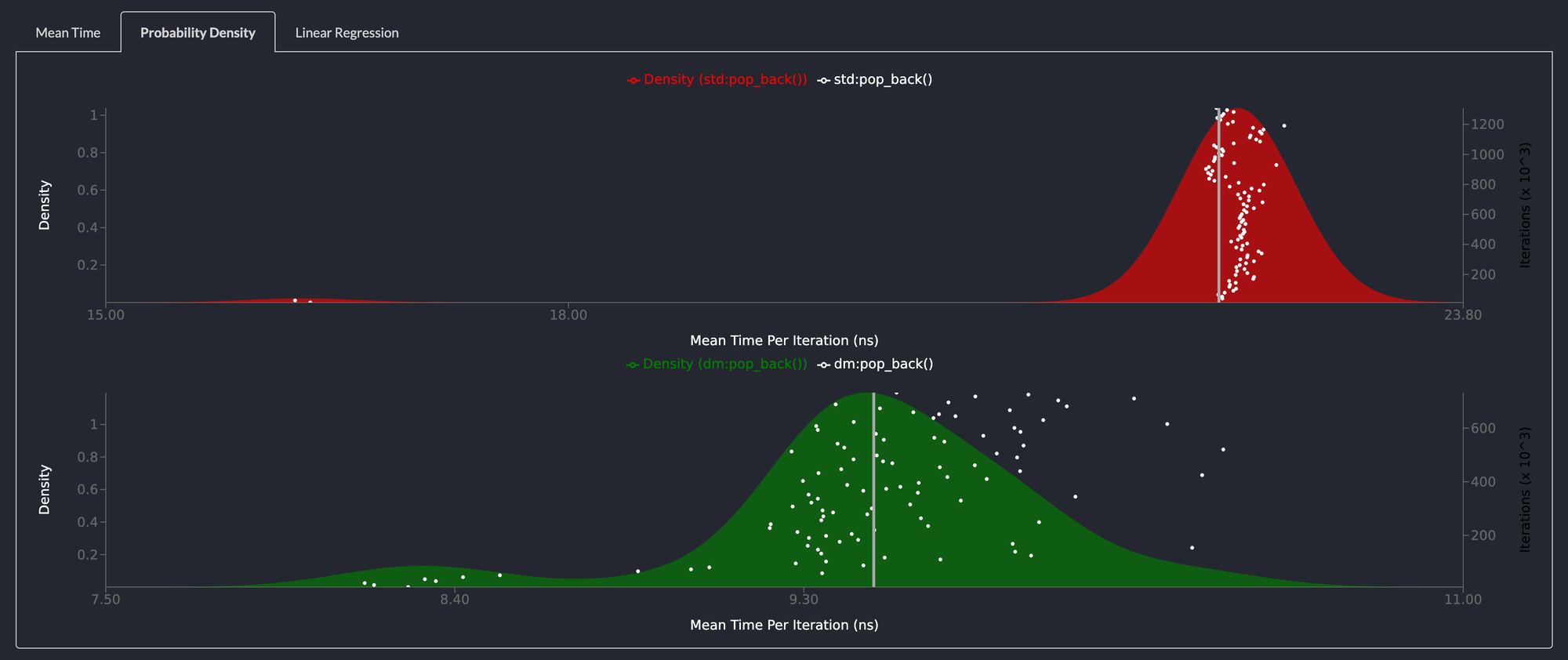
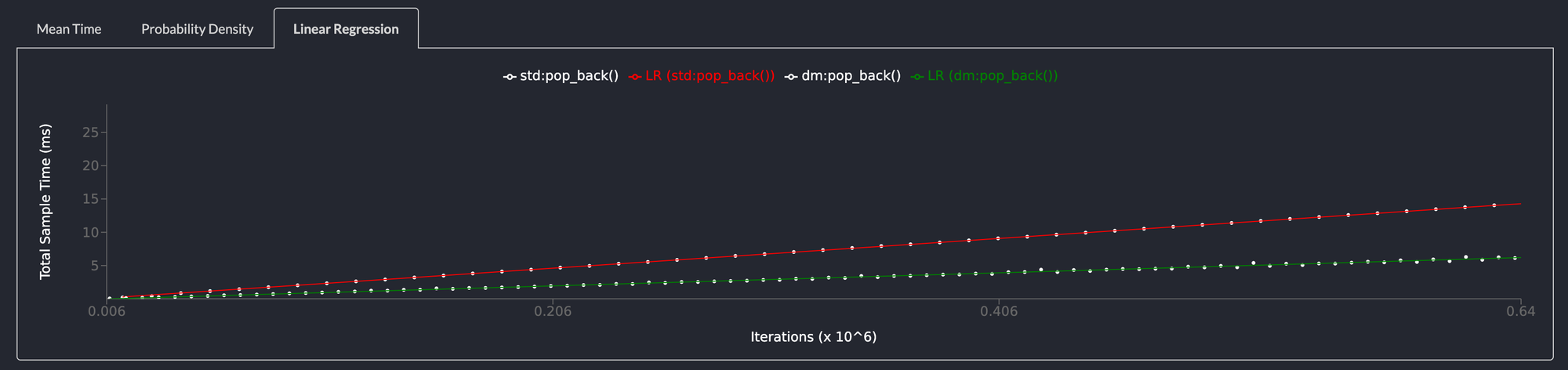
pop_back() is also more than 2x faster than std::collections::LinkedList
Removing elements from the back of the list also shows the same performance characteristics as pop_front() and for the same reasons.
Pushing to the middle of the list is 35% faster
The standard library LinkedList doesn't allow pushing to the middle of the list in constant time so this benchmark compared pushing to the middle of the deepmesa list vs pushing to the front of the std::collections::LinkedList.
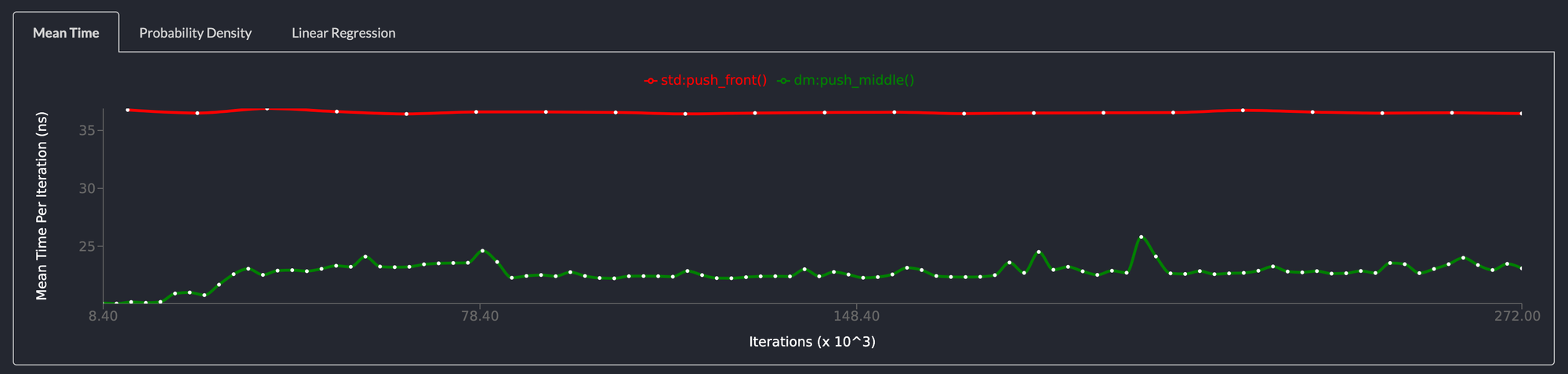
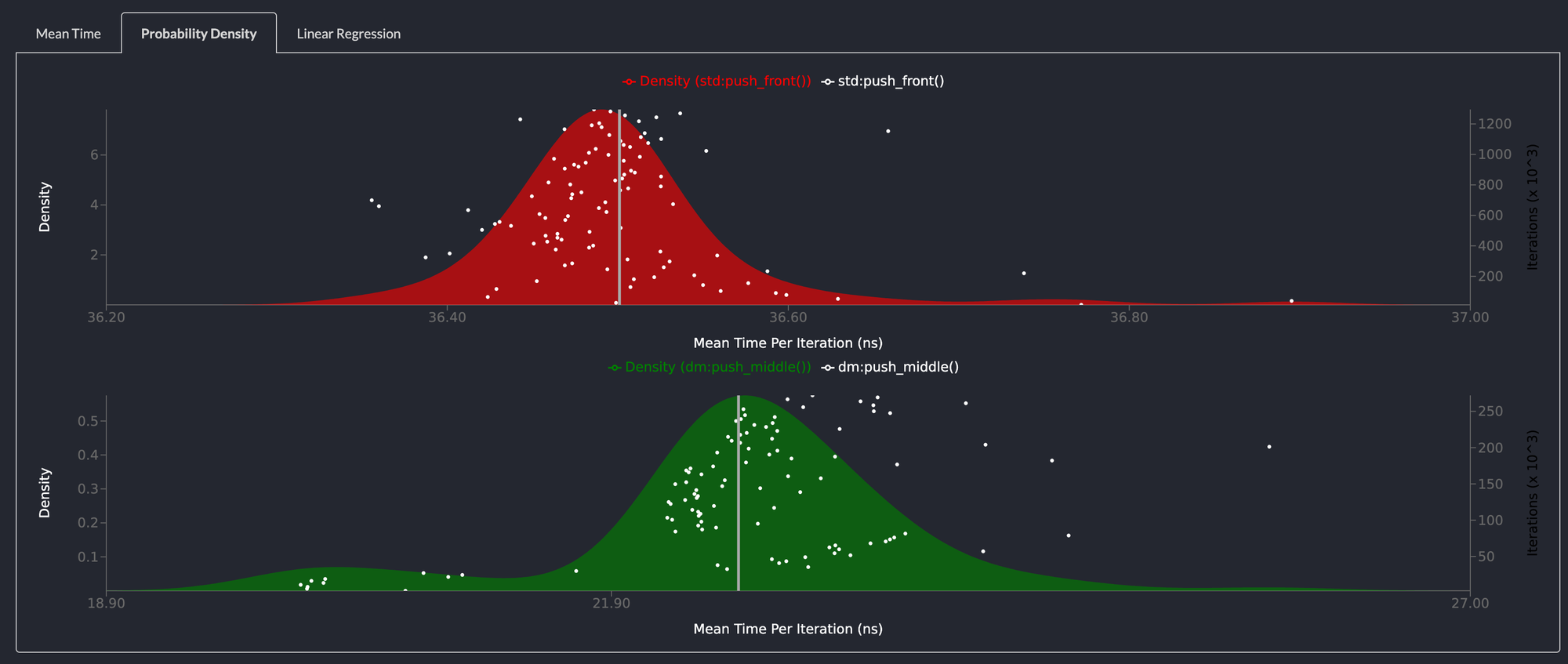
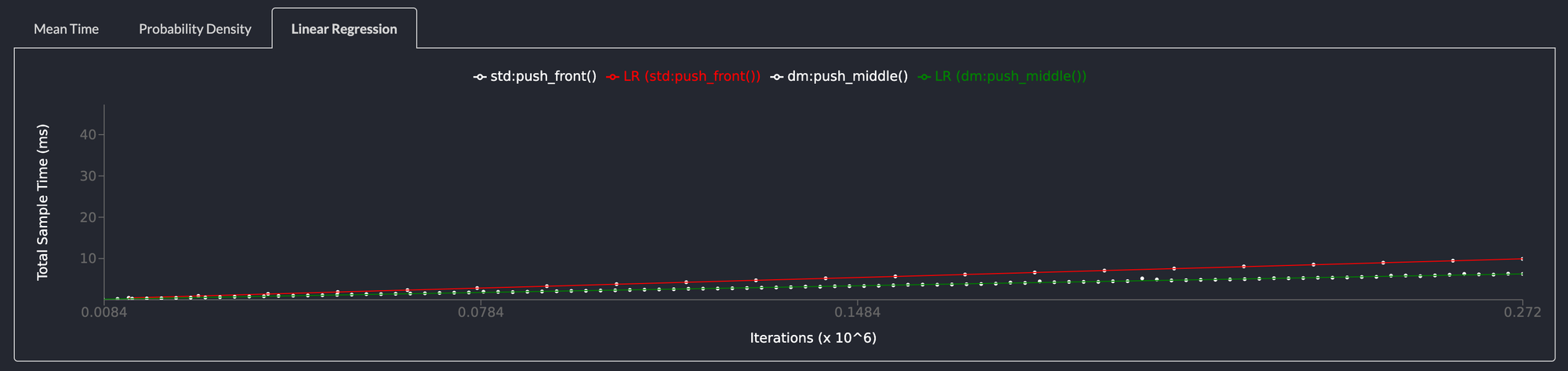
The deepmesa linkedlist is twice as fast as the std::collections::LinkedList and is a drop in replacement.